VoiceCloner: Mi Asistente para Tutoriales de Programación
Publicado el miércoles, 9 julio 2025
Introducción: El Reto de Compartir Conocimiento (y Optimizar el Tiempo)
Como desarrollador, siempre he buscado formas de consolidar mi aprendizaje. Los tutoriales en vídeo de programación son una excelente manera de repasar conceptos y compartir conocimiento. Sin embargo, me encontré con un desafío: la creación de vídeos consumía una cantidad desproporcionada de tiempo. La grabación, la edición y, sobre todo, la preparación del guion y la locución, convertían un vídeo de 6-10 minutos en un proceso de 6 horas. Mi objetivo principal era practicar con el código, no convertirme en un editor de vídeo a tiempo completo. Fue entonces cuando me pregunté: ¿Y si pudiera automatizar la parte de la voz narrativa?
El Origen de la Idea: Optimización con Inteligencia Artificial
La solución que ideé fue desarrollar una herramienta de clonación de voz. La idea era simple pero potente: yo escribiría el guion explicativo del tutorial, y mi aplicación se encargaría de "leerlo" con una voz sintetizada y clonada, mientras yo me concentraba en mostrar el código y las funcionalidades visuales en pantalla. Esto no solo me permitiría reducir drásticamente el tiempo de producción (de 6 horas a solo 2 por vídeo, un ahorro de un 66% de tiempo), sino que también me liberaría para dedicarme a lo que realmente me apasiona: la codificación y la resolución de problemas.
Tecnologías Empleadas
Este proyecto se construyó enteramente en Python, aprovechando la potencia de varias bibliotecas clave:
- Tkinter: Para la creación de la interfaz gráfica de usuario (GUI). Elegí Tkinter por su simplicidad e integración nativa con Python, lo que me permitió crear una herramienta de escritorio funcional rápidamente.
- Coqui-TTS (XTTS-v2): El corazón del clonador de voz. Coqui-TTS es una potente librería de código abierto para "Text-to-Speech" (conversión de texto a voz). Específicamente, utilicé el modelo XTTS-v2, conocido por su capacidad de clonación de voz realista y soporte multilingüe.
- PyTorch: Como framework de aprendizaje automático subyacente para el modelo XTTS-v2.
- threading: Para permitir que la síntesis de voz se ejecute en segundo plano, manteniendo la interfaz de usuario responsiva y evitando bloqueos durante procesos largos.
- os, json, time, filedialog, messagebox: Para la gestión de archivos, persistencia de datos (librería de voces), manejo de tiempo y retroalimentación al usuario.
Funcionalidades Clave
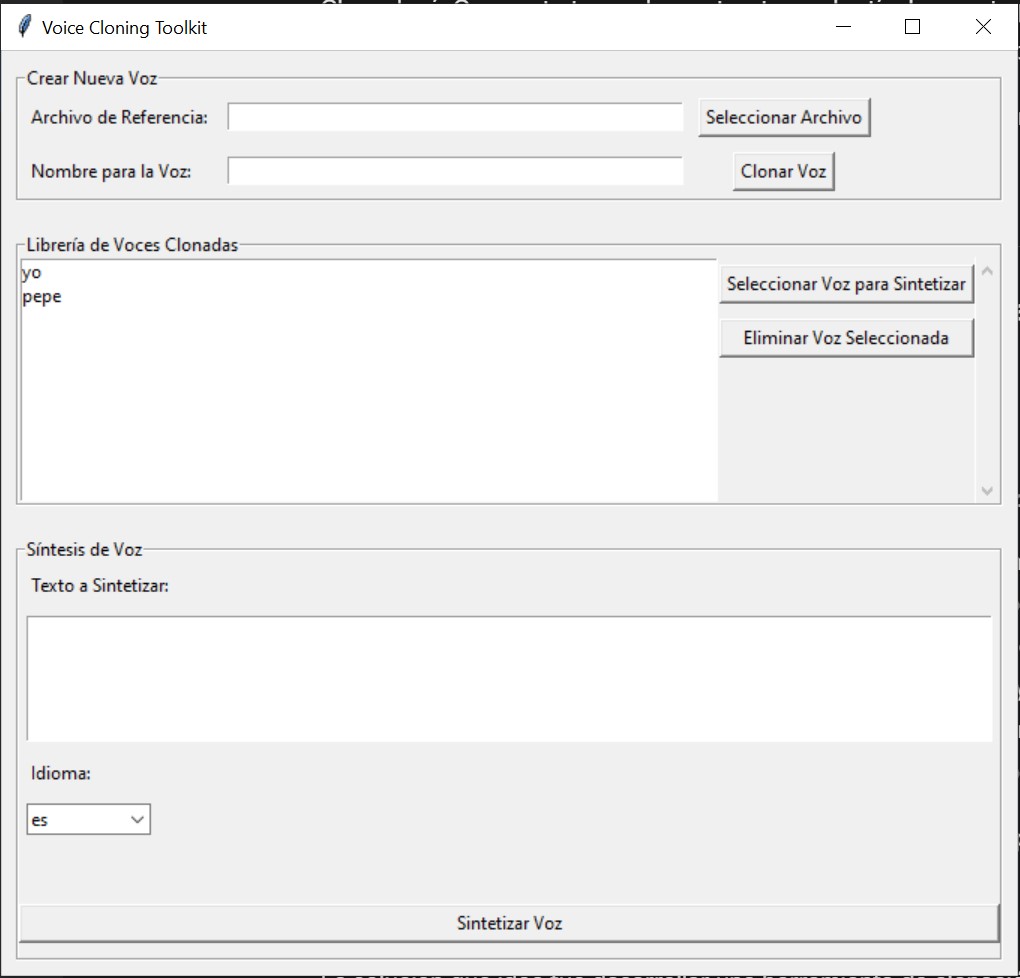
La aplicación está diseñada para ser intuitiva y eficiente, dividida en tres secciones principales:
Creación de Nueva Voz:
- Selección de Archivo de Referencia: El usuario puede seleccionar un archivo de audio WAV (de unos pocos segundos de duración) que servirá como muestra para la voz a clonar.
- Nombre de la Voz: Se asigna un nombre único a la voz clonada.
- Clonar Voz: Al hacer clic, la aplicación utiliza el modelo XTTS-v2 para "aprender" las características de la voz del archivo de referencia y genera un archivo .pth (un archivo de modelo PyTorch) que representa esa voz clonada. Este proceso se realiza con un texto de prueba interno y se guarda el modelo junto con un registro de la voz en una librería JSON.
Librería de Voces Clonadas:
- Lista de Voces: Muestra todas las voces que el usuario ha clonado previamente y guardado en la librería.
- Seleccionar Voz para Sintetizar: Permite elegir una voz de la lista para usarla en la síntesis de texto.
- Eliminar Voz Seleccionada: Permite borrar una voz clonada, tanto de la interfaz como su archivo .pth asociado y su registro en la librería JSON.
Síntesis de Voz:
- Texto a Sintetizar: Un área de texto donde el usuario introduce el guion o cualquier texto que desea convertir a voz.
- Idioma: Un selector para especificar el idioma del texto, vital para que el modelo genere una voz adecuada (el modelo XTTS-v2 soporta varios idiomas, incluyendo español, inglés, francés, etc.).
- Estimación de Tiempo: Una funcionalidad inteligente que, basándose en el historial de síntesis anteriores, estima el tiempo que tardará en generar el audio, proporcionando al usuario una expectativa realista.
- Sintetizar Voz: Inicia el proceso de conversión de texto a voz, utilizando la voz clonada y el idioma seleccionados. El audio resultante se guarda como un archivo WAV en la ubicación que el usuario elija. Esta operación se ejecuta en un hilo separado para mantener la interfaz de usuario fluida.
Impacto y Conclusiones
Este proyecto ha transformado mi forma de abordar la creación de contenido educativo. La reducción de tiempo de producción es monumental, permitiéndome enfocar mi energía en la calidad del código y la claridad de los conceptos, en lugar de en tareas repetitivas de post-producción. El VoiceCloner es un testimonio de cómo la inteligencia artificial y las herramientas de código abierto pueden ser aplicadas para resolver problemas reales de productividad en el día a día de un desarrollador. Ha sido un desafío enriquecedor trabajar con modelos de ML complejos y construir una interfaz de usuario práctica, y estoy emocionado de ver cómo esta herramienta seguirá evolucionando y apoyando mis futuros tutoriales.
Encuéntralo en: Clonador de voces
Volver al Portafolio